OverlordBot is an AI AWACS that listens to Voice communications on Simple Radio Standalone and uses machine learning to understand, and reply to, common AWACS radio calls.
The bot code is completely free & open source.
So, a bot that you speak to and it talks back with ATC and AWACs info within DCS. Uses SRS as the bridge to listen/transmit. Usually found running servers like GAW hoggit’s, so a good way to play with it there - you just use SRS with nothing to install your side. Server info here:
Setting up your own server is quite the job, as it uses a bunch of tacview importing, DB and Azure speech services, although you can ‘free tier’ a lot of these.
It’s a complicated back-end for sure, so amazing work for them to get it going. The big downsides are the use of paid services for the speech input, as in you have to train the Azure model to recognize your pronunciations of your callsign and the various airport names (I can barely say them in English, poor Azure). For the speech output the nice voices also cost money.
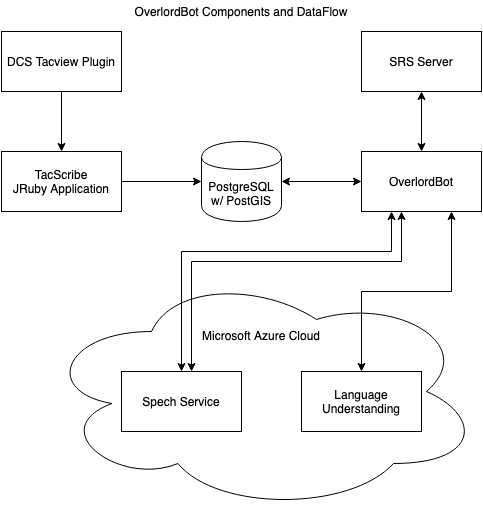
The architecture is made up of a series of different projects:
One really nice thing is that TacScribe app, which essentially reads the TacView export from DCS live and then populates a PostgresSQL GIS set of tables - I can see that being useful for all sorts of things when you need a georeferenced live view of a running DCS server.
It certainly looks like a fun project for someone, so great they got it all working.
Looking forward to a point when there will be good open source pretrained speech recognition models. A typical gamer machine should eat the inferrence step of such a model for breakfast (maybe not while running DCS on the side, though).
I guess this project could have also used the local Windows PC services a bit more as well - things like VoiceAttack are just layers over the win32 training/local recognition ‘on device’. As people have to run SRS anyway, and DCS on the client is Windows only, that would have been an alternative way to go. The speech output Azure voices are very good though.
OverlordBot Dev here. Someone just linked me to this thread so let me add a few extra bits.
Setup is indeed not for the faint-hearted. About… 30’ish servers have done it and I think 3 or 4 gave up during the process. I am in the thinking about removing the need for TacScribe and the PostgreSQL database as intermediaty systems to simplify things.
I chose the current architecture indeed so that other people could use the Database as a source for things like online maps but no one has taken advantage of that so it is extra complexity that is probably unneeded. I have recently written an alternative program to TacScribe that gets data out of DCS without the need for Tacview since some servers were adamant that they would not run it.
As far as cost goes, only the Hoggit servers are actually on the paid tiers of Azure because they are running something like 15 channels on 4 servers with a decent amount of radio traffic. Everyone else is running on the free tiers and you can even have the nicer “neural” voices now on the free tier.
Enough people have submitted voice training that the bot is pretty good at recognising most calls now (apart from Batumi which it just cannot understand.) without the need for additional training.
The people who need to submit voice training now tend to be the ones running awkward callsigns. Every server so far is using a shared trained model that I update and fan out to everyone (although servers could choose to use their own if they wanted to).
For the voice training using the win32 voice recognition didn’t work (Results were unintelligable garbage basically) and since the bot needs to recognise multiple people’s voices we needed something better. Another reasong for using azure was removing the need to clients to install / run anything extra which was a concious decision.
Given the fact that every server apart from Hoggit are on the free tier I don’t really have an incentive to try out other voice recognition and language understanding systems since it would be a lot of work to test.